Machine-Learning für die Waldtypisierung
Beitragsinhalt
Anwendungen kommen bei der Typisierung von Wald zum Einsatz. Hochaufgelöste Daten liefern eine wichtige Entscheidungsgrundlage für die Bewirtschaftung von Wäldern.
„Keine Ahnung?“ – das gibt es nicht mehr! Wenn wir etwas nicht wissen, dann fragen wir einfach eine Suchmaschine im Internet. Sie liefert uns in Sekunden die passende Antwort unter Verwendung ausgefeilter Algorithmen. Können diese neuen Methoden auch in der Naturgefahrenforschung verwendet werden? Was ist derzeit möglich und was ist noch zu erwarten?
Was Machine-Learning ist
Unter „Machine-Learning” werden Algorithmen zusammengefasst, die aus der Statistik kommen und mehr oder weniger komplexe Zusammenhänge aus großen Datensätzen erfassen können. Machine-Learning wird als Teilbereich der künstlichen Intelligenz bezeichnet, denn es werden bei beiden dieselben Algorithmen verwendet. Um von künstlicher Intelligenz sprechen zu können, ist es aber erforderlich, dass scheinbar intelligente Schlussfolgerungen vom Algorithmus gezogen werden. Das kann etwa das autonome Autofahren sein, weil dabei ein Zusammenspiel aus Hören, Sehen, Entscheiden und Handeln nötig ist. Aber auch die Spracherkennung und die gezielte Aktion darauf deuten auf künstliche Intelligenz hin, wie etwa bei der Übersetzung in andere Sprachen.
Einführung zu Machine-Learning
Beim Machine-Learning versuchen die Algorithmen Strukturen und Muster in großen Datensätzen zu finden. Das kann beispielsweise genutzt werden, um Datenausreißer zu identifizieren – seien es falsche Messwerte oder seltene (Extrem-)Werte. Diese Art der Anwendung von Machine-Learning wird Unsuperwised-Learning oder unüberwachtes Lernen genannt. Das Gegenstück dazu ist das Supervised-Learning oder überwachtes Lernen. Dabei werden Zielvariablen und Eingangsvariablen definiert.
Mit Machine-Learning wird ein Modell gebildet, das die Eingangsdaten verwendet und die Zielvariablen berechnet. Aus einem vorher angefertigten Datensatz (Trainingsdatensatz) erlernt das Modell das Regelwerk. Angewendet auf neue Eingangsdaten werden die Werte für die Zielvariablen kalkuliert. Das überwachte Lernen funktioniert sowohl für klassifizierte Daten als auch für numerische Werte. Allerdings wird ein möglichst großer und fehlerfreier Datensatz zum Training vorausgesetzt.
Dringt man tiefer in die Fachliteratur ein, dann stößt man auf weitere Begriffe, wie Semi-Supervised Learning oder teilüberwachtes Lernen und Reinforcement-Learning (verstärktes Lernen). Sie weisen besondere Eigenschaften auf, wie es etwa beim Herausfinden aus einem Labyrinth erforderlich ist.
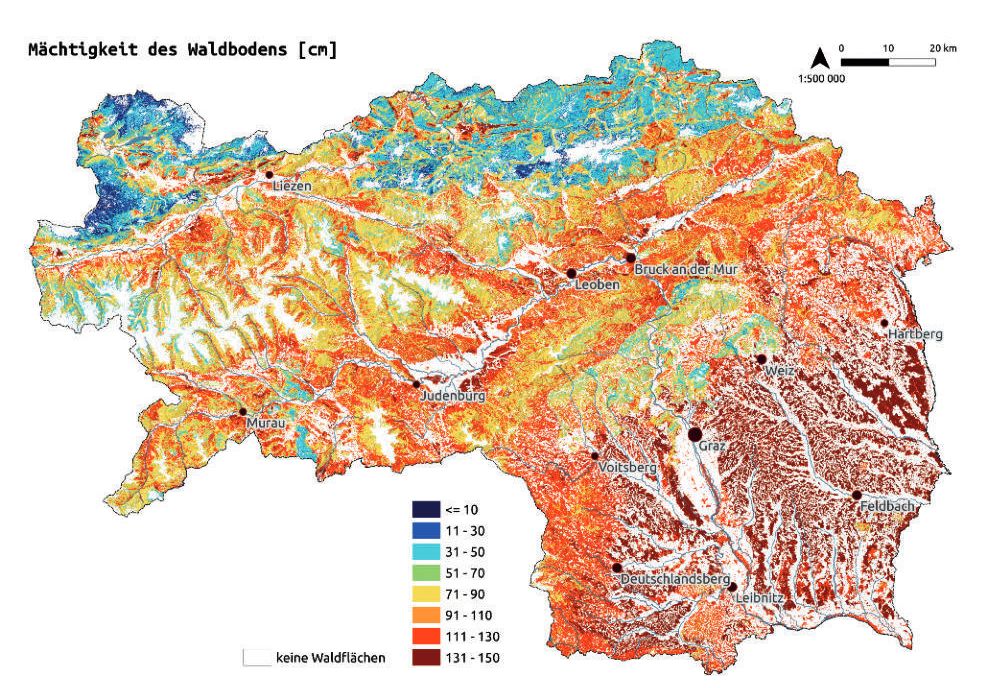
Digitale Kartierung von Boden im Rahmen von FORSITE
Boden ist in unterschiedliche Schichten mit unterscheidbaren Eigenschaften wie Korngrößenzusammensetzung, Lagerungsdichte, Porosität, pH-Wert, Kohlenstoffgehalt u.a. gegliedert. Neben dem geologischen Ausgangssubstrat bestimmen die Art und Form der Landbedeckung, Landnutzung, das Relief und die klimatischen Rahmenbedingungen die Eigenschaften des Bodens. Großen Einfluss hat auch die Zeitdauer, die zur Bodenbildung zur Verfügung steht.
Im Projekt „Dynamische Waldtypisierung Steiermark“ (FORSITE) stand man vor der Herausforderung, aus 1800 terrestrisch erhobenen und teilweise beprobten Bodenprofilen flächige Karten zu den physikalischen, chemischen und hydrologischen Eigenschaften des Untergrundes zu generieren. Dieser Prozess der digitalen Kartierung (engl. digital mapping) wurde über maschinelles Lernen, in diesem Falle einem künstlichen neuronalen Netz, bewerkstelligt.
Als Grundlage der räumlichen Interpolation wurden zahlreiche Datensätze zu den klimatischen, topografischen und geologischen Gegebenheiten aufbereitet bzw. abgeleitet und dem Algorithmus als Vorhersagevariablen (engl. predictors) zur Verfügung gestellt. Bei der Berechnung wurde der Weg gewählt, dass eine Vielzahl an Zielvariablen gemeinsam berechnet wurde. Damit konnte vermieden werden, dass sich einzelne Zielvariablen gegenseitig widersprechen, da das neuronale Netz gleichzeitig auf alle Variablen angepasst wurde. Da über 100 Zielvariablen mit einer räumlichen Auflösung von 10 x 10 m berechnet wurden, war die optimale Nutzung und Leistungsfähigkeit der Rechner eine große Herausforderung.
Ausblick und Kritik. Wohin führt uns die künstliche Intelligenz (KI)?
Machine-Learning und künstliche Intelligenz sind auch in Wirtschaftsfragen, in der Medizin und der Technik allgegenwärtig. Es werden kurzfristige Schwankungen in den Aktienmärkten genutzt, um Investments zu tätigen. Das erfolgt schneller, wie es ein Mensch machen könnte. Tomografien des Körpers werden analysiert und das mit einer Präzision, an die der Mensch nicht herankommt.
Es gibt auch schon eine Publikation, die ausschließlich von einer künstlichen Intelligenz geschrieben wurde. Und kürzlich gewann ein Gemälde einen Preis, das von einer künstlichen Intelligenz gemalt wurde. Grundsätzlich muss eine künstliche Intelligenz nicht immer recht haben. Der Algorithmus ist zwar so ausgelegt, dass er zumindest ein Optimum erreicht. Es bleibt aber ein Restrisiko, dass es eine bessere Lösung für die Fragestellung gibt. Weiters können sich Menschen entmündigt fühlen, wenn sie selbst die Entscheidung nicht mehr nachvollziehen können, da das menschliche Gehirn im Gegensatz zu mathematischen Verfahren nur sehr wenige Dimensionen begreifen kann.
Welche Produkte können wir für Naturgefahren erwarten?
Überall dort, wo enorme Datenmengen anfallen, wird Machine-Learning verstärkt zum Einsatz kommen. Fernerkundungsmethoden sind solche Datenquellen. Sie sind auch deshalb für Naturgefahren interessant, weil Prozesszonen meist eine Gefahr für Personen und technische Anlagen darstellen. Großflächige terrestrische Kartierungen sind auf Grund der notwendigen zeitlichen und personellen Ressourcen kaum vorstellbar. Hier werden Verfahren des Digital-Mappings zunehmend an Bedeutung gewinnen. Die entwickelten Verfahren sind dabei auf unterschiedliche Variablen der Geo-, Pedo- und Hydrosphäre anwendbar, sofern die geeigneten Prädiktoren bereitgestellt werden können.
Weitere Informationen
Das Projekt FORSITE erhielt für seine herausragenden Leistungen von Energy Globe Österreich eine Auszeichnung: www.energyglobe.at
Wissen zum Vertiefen:
data.steiermark.at
www.agrar.steiermark.at
https://www.sciencedirect.com/science/article/pii/S2666827022000809?via%3Dihub